4 bit ripple carry counter truth table calculator
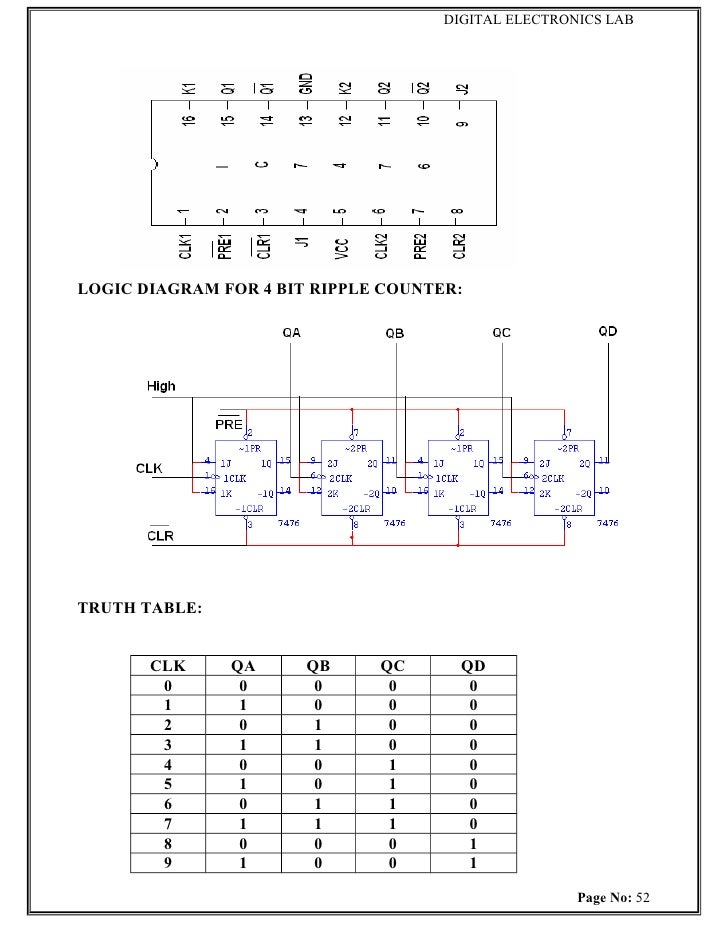
Figure 8 is the parallel prefix graph of a Han-Carlson adder. This adder has a hybrid design combining stages from the Brent-Kung and Kogge-Stone adder. The basic idea in the conditional sum adder is to generate two sets of outputs for a given group of operand bits, say, k bits. Each set includes k sum bits and an outgoing carry.
One set assumes that the eventual incoming carry will be zero, while the other assumes that it will be one. Once the incoming carry is known, we need only to select the correct set of outputs out of the two sets without waiting for the carry to further propagate through the k positions.
This process can, in principle, be continued until a group of size 1 is reached. The above idea is applied to each of groups separately. The underlying strategy of the carry-select adder is similar to that of the conditional-sum adder. Each group generates two sets of sum bits and an outgoing carry.
One set assumes that the incoming carry into the group is 0, the other assumes that it is 1. When the incoming carry into the group is assigned, its final value is selected out of the two sets. Unlike the conditional-sum adder, the sizes of the kth group is chosen so as to equalize the delay of the ripple-carry within the group and the delay of the carry-select chain from group 1 to group k.
In this generator, the group lengths follow the simple arithmetic progression 1, 1, 2, 3, A carry-skip adder reduces the carry-propagation time by skipping over groups of consecutive adder stages. The carry-skip adder is usually comparable in speed to the carry look-ahead technique, but it requires less chip area and consumes less power. The adder structure is divided into blocks of consecutive stages with a simple ripple-carry scheme.
This signal can be used to allow an incoming carry to skip all the stages within the block and generate a block-carry-out. Figure 12 shows an 8-bit carry-skip adder consisting of four fixed-size blocks, each of size 2. The fixed block size should be selected so that the time for the longest carry-propagation chain can be minimized. Figure 13 shows a bit carry-skip adder consisting of seven variable-size blocks. This optimal organization of block size includes L blocks with sizes k1, k2, This reduces the ripple-carry delay through these blocks.
Please note that the delay information of carry-skip adders in Reference data page is simply estimated by using false paths instead of true paths. Figure 14 compares the delay information of true paths and that of false paths in the case of Hitachi 0.
Table 1 shows hardware algorithms that can be selected for multi-operand adders in AMG, where the bit-level optimized design indicates that the matrix of partial product bits is reorganized to optimize the number of basic components. Array is a straightforward way to accumulate partial products using a number of adders. The n-operand array consists of n-2 carry-save adder.
Figure 15 shows an array for operand, producing 2 outputs, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs. Wallace tree is known for their optimal computation time, when adding multiple operands to two outputs using carry-save adders.
The Wallace tree guarantees the lowest overall delay but requires the largest number of wiring tracks vertical feedthroughs between adjacent bit-slices. The number of wiring tracks is a measure of wiring complexity.
Figure 16 shows an operand Wallace tree, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs. Balanced delay tree requires the smallest number of wiring tracks but has the highest overall delay compared with the Wallace tree and the overturned-stairs tree.
Figure 17 shows an operand balanced delay tree, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs.
Overturned-stairs tree requires smaller number of wiring tracks compared with the Wallace tree and has lower overall delay compared with the balanced delay tree. Figure 18 shows an operand overturned-stairs tree, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs. Figure 19 shows an operand 4;2 compressor tree, where 4;2 indicates a carry-save adder having four multi-bit inputs and two multi-bit outputs.
Dadda tree is based on 3,2 counters. To reduce the hardware complexity, we allow the use of 2,2 counters in addition to 3,2 counters. Given the matrix of partial product bits, the number of bits in each column is reduced to minimize the number of 3,2 and 2,2 counters. A 7,3 counter tree is based on 7,3 counters. To reduce the hardware complexity, we allow the use of 6,3 , 5,3 , 4,3 , 3,2 , and 2,2 counters in addition to 7,3 counters.
We employ Dadda's strategy for constructing 7,3 counter trees. Redundant binary RB addition tree has a more regular structure than an ordinary CSA tree made of 3,2 counters because the RB partial products are added up in the binary tree form by RB adders.
The RB addition tree is closely related to 4;2 compressor tree. Note here that the RB number should be encoded into a vector of binary digit in the standard binary-logic implementation.
Once the incoming carry is known, we need only to select the correct set of outputs out of the two sets without waiting for the carry to further propagate through the k positions.
This process can, in principle, be continued until a group of size 1 is reached. The above idea is applied to each of groups separately. The underlying strategy of the carry-select adder is similar to that of the conditional-sum adder.
Each group generates two sets of sum bits and an outgoing carry. One set assumes that the incoming carry into the group is 0, the other assumes that it is 1. When the incoming carry into the group is assigned, its final value is selected out of the two sets. Unlike the conditional-sum adder, the sizes of the kth group is chosen so as to equalize the delay of the ripple-carry within the group and the delay of the carry-select chain from group 1 to group k.
In this generator, the group lengths follow the simple arithmetic progression 1, 1, 2, 3, A carry-skip adder reduces the carry-propagation time by skipping over groups of consecutive adder stages.
The carry-skip adder is usually comparable in speed to the carry look-ahead technique, but it requires less chip area and consumes less power. The adder structure is divided into blocks of consecutive stages with a simple ripple-carry scheme. This signal can be used to allow an incoming carry to skip all the stages within the block and generate a block-carry-out. Figure 12 shows an 8-bit carry-skip adder consisting of four fixed-size blocks, each of size 2.
The fixed block size should be selected so that the time for the longest carry-propagation chain can be minimized. Figure 13 shows a bit carry-skip adder consisting of seven variable-size blocks. This optimal organization of block size includes L blocks with sizes k1, k2, This reduces the ripple-carry delay through these blocks.
Please note that the delay information of carry-skip adders in Reference data page is simply estimated by using false paths instead of true paths. Figure 14 compares the delay information of true paths and that of false paths in the case of Hitachi 0.
Table 1 shows hardware algorithms that can be selected for multi-operand adders in AMG, where the bit-level optimized design indicates that the matrix of partial product bits is reorganized to optimize the number of basic components. Array is a straightforward way to accumulate partial products using a number of adders. The n-operand array consists of n-2 carry-save adder. Figure 15 shows an array for operand, producing 2 outputs, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs.
Wallace tree is known for their optimal computation time, when adding multiple operands to two outputs using carry-save adders. The Wallace tree guarantees the lowest overall delay but requires the largest number of wiring tracks vertical feedthroughs between adjacent bit-slices. The number of wiring tracks is a measure of wiring complexity. Figure 16 shows an operand Wallace tree, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs.
Balanced delay tree requires the smallest number of wiring tracks but has the highest overall delay compared with the Wallace tree and the overturned-stairs tree. Figure 17 shows an operand balanced delay tree, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs.
Overturned-stairs tree requires smaller number of wiring tracks compared with the Wallace tree and has lower overall delay compared with the balanced delay tree.
Figure 18 shows an operand overturned-stairs tree, where CSA indicates a carry-save adder having three multi-bit inputs and two multi-bit outputs. Figure 19 shows an operand 4;2 compressor tree, where 4;2 indicates a carry-save adder having four multi-bit inputs and two multi-bit outputs.
Dadda tree is based on 3,2 counters. To reduce the hardware complexity, we allow the use of 2,2 counters in addition to 3,2 counters. Given the matrix of partial product bits, the number of bits in each column is reduced to minimize the number of 3,2 and 2,2 counters. A 7,3 counter tree is based on 7,3 counters.
To reduce the hardware complexity, we allow the use of 6,3 , 5,3 , 4,3 , 3,2 , and 2,2 counters in addition to 7,3 counters. We employ Dadda's strategy for constructing 7,3 counter trees. Redundant binary RB addition tree has a more regular structure than an ordinary CSA tree made of 3,2 counters because the RB partial products are added up in the binary tree form by RB adders.
The RB addition tree is closely related to 4;2 compressor tree. Note here that the RB number should be encoded into a vector of binary digit in the standard binary-logic implementation.
In this generator, we employ a minimum length encoding based on positive-negative representation. Partial products are generated with Radix-4 modified Booth recoding. The Booth recoding of the multiplier reduces the number of partial products and hence has a possibility of reducing the amount of hardware involved and the execution time. The PPG stage first generates partial products from the multiplicand and multiplier in parallel.
The PPA stage then performs multi-operand addition for all the generated partial products and produces their sum in carry-save form.