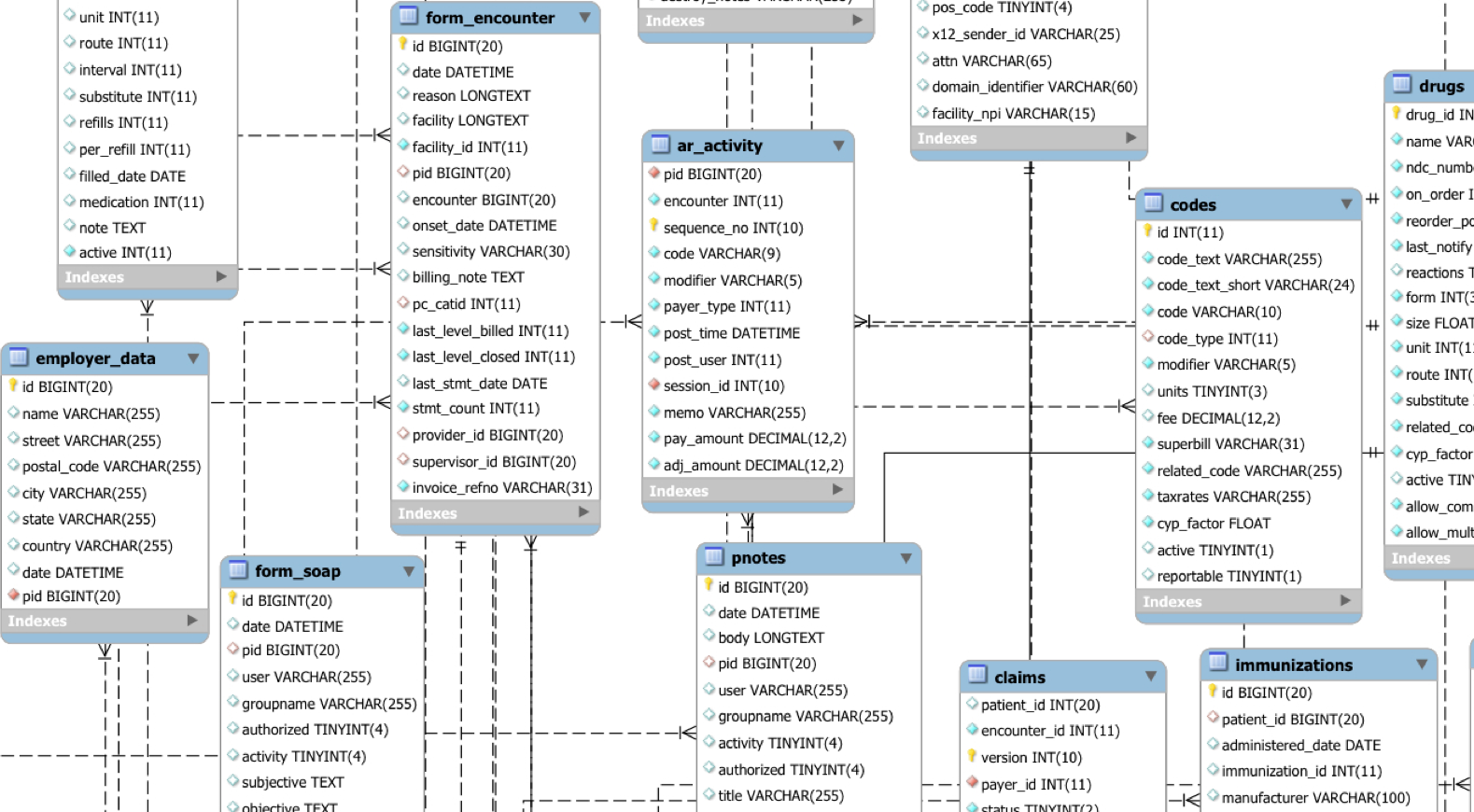
The Bitcoin Blockchain PostgresSQL Schema
5 stars based on
66 reviews
In a previous post I wrote some initial thoughts on storing the blockchain in Postgres. This post documents the latest incarnation of the SQL schema used to store the blockchain as well as thoughts on why it was decided to blockchain database schema in sql this way. The Bitcoin blockchain consists of blocks. A block is a set of transactions. A block also contains some block-specific informationsuch as the nonce for the Proof-Of-Work validating the block.
A transaction consist of inputs and outputs. The inputs reference outputs from prior transactions, which may include transactions in the same block. When an output is referenced by an input, the output is considered spent in its entirety, i. While double-spends do imply that one of blockchain database schema in sql transactions is invalid, it is not uncommon for double-spends to exist at least for a period of time, thus the database blockchain database schema in sql needs to allow them.
Naturally, the output value cannot exceed the input value, but it is normal for the output value to be less than the input value. The discrepancy between the input and the output is the transaction fee and is taken by the miner solving the block in which the transaction is included. The blockchain database schema in sql transaction in a block is referred to as the coinbase. Coinbase is a special transaction where the inputs refer to a non-existent transaction hash of all zeros.
Coinbase outputs are the sum of all the fees and the miner reward. Curiously it is possible for the same coinbase transaction to be included in more than one block, and there is at least one case of this in the blockchain. The implication of this is that the second instance of such a transaction is unspendable. This oddity was addressed by a change in the consensus which requires the block height to be referenced in the coinbase and is since then no longer possible see BIP The same transaction can be included in more than one block.
This is common during chain splits, i. Chain splits also cause multiple blocks to have the same height which implies that height alone cannot identify a particular block or that it is unique.
With introduction of SegWit transactions also blockchain database schema in sql witness data. Witness is stored at the end of a transaction as a list where each entry corresponds to an input. A witness entry is in turn a list, because an input can have multiple signatures aka witness. In the blockchain blocks and transactions are always referred to through their hash.
A hash is an array of 32 bytes. While in theory we could build a schema which relies on the hash as the record identifier, in practice it is cumbersome compared to the traditional integer ids. Firstly, 32 bytes is four times larger than a BIGINT and eight times larger than an INT, which impacts greatly the amount of space required to store inputs and outputs as well as degrades index performance.
There is also an ambiguity in how the hash is printed versus how it is stored. While the SHA standard does not specify the endian-ness of the hash and refers to it as an array of bytes, Satoshi Nakomoto decided to treat hashes as little-endian bit integers. The implication being that when the hash is printed e.
Using integer ids creates a complication in how inputs reference outputs. This is an easily justifiable optimization, without it to lookup the input transaction blockchain database schema in sql require first finding the transaction integer id. The downside is blockchain database schema in sql during the initial import maintaining the hash to integer id correspondence in blockchain database schema in sql efficient manner is bit of a challenge.
Postgres 4-byte INT is signed, which presents us with two options: We are opting for the latter as preserving space is more important and for as long as all the bits are correct, whether the integer is interpreted as signed or unsigned blockchain database schema in sql of no consequence. Blocks are collections of transactions.
It is a many-to-many relationship as multiple blocks can include to the same transaction. The CBlockHeader is defined in Core as follows:.
Columns orphanstatusfilen and filepos are from the CBlockIndex class which is serialized in LevelDb and not formally part of the blockchain. It contains information about the file in which the block was stored on-disk as far as Core is concerned. This information is only necessary for debugging purposes, also note that it is unique to the particular instance of the Core database, i. Same is true with respect to transaction id. Not only do we need to record that a transaction is included in a block, but also its exact position relative to other transactions, denoted by the n column:.
A transaction is a collection of inputs and outputs. In Core an output is represented by blockchain database schema in sql CTxOut class:. The spent column is an optimization, it is not part of the blockchain. An output is spent if later in the blockchain there exists an input referencing it. The reason Core does it this way is because by default it does not index transactions, i. Core actually does blockchain database schema in sql have a way of quickly retrieving a transaction from the store as there generally is no need for such retrieval as part of a node operation, while the UTXO Set is both sufficient and smaller than a full transaction index.
Since in Postgres we have no choice but to index transactions, there is no benefit in having UTXOs as a separate table, the spent flag serves this purpose instead. The UTXO Set does not include any outputs with the value of 0, since there is nothing to spend there even though no input refers to them and they are not technically spent.
An input in Core is represented by the CTxIn class, which looks like this:. The COutPoint class is a combination of a hash and an integer representing an output.
As we already mentioned above witness is stored as opaque bytes. Blocks and transactions are indexed by id as their primary index. Blocks also need an index blockchain database schema in sql hash uniqueas well as on height and on prevhash not unique.
Transactions need a unique index on the txid. Finally, we need a basic set of foreign key constraints blockchain database schema in sql ensure the integrity between all the related tables. Every time an input is inserted, it locates the database id of the transaction it spends as well as updates the spent flag of the corresponding output. Technically it is done using two triggers for performance reasons.
Deferring constraints can speed up inserts considerably, for this reason the code that updates spent is in a separate AFTER trigger. While this is not part of the schema, I thought it would be of interest to the readers.
An orphaned block is a block to which no other prevhash refers. At the time of a chain split we start out with two blocks referring to the same block as previous, but the next block to arrive will identify one blockchain database schema in sql the two as its previous thereby orphaning the other of the pair.
To identify orphans we need to blockchain database schema in sql the chain backwards starting blockchain database schema in sql the highest height. Any block that this walk does not visit is an orphan. Devising this schema was surprisingly tedious and took many trial and error attempts to reimport the entire blockchain which collectively took weeks. Many different variations on how to optimize operations were attempted, for example using an expression index to only index a subset of a hash first 10 bytes are still statistically uniqueetc.
I would love to hear comments from the database experts out there. Row Ids and Hashes In the blockchain blocks and transactions are always referred to through their hash. Blocks Blocks are collections of transactions. The CBlockHeader is defined in Core as follows: Please enable JavaScript to view the comments powered by Disqus.