



Bot komen di status sendiri lagi
30 comments
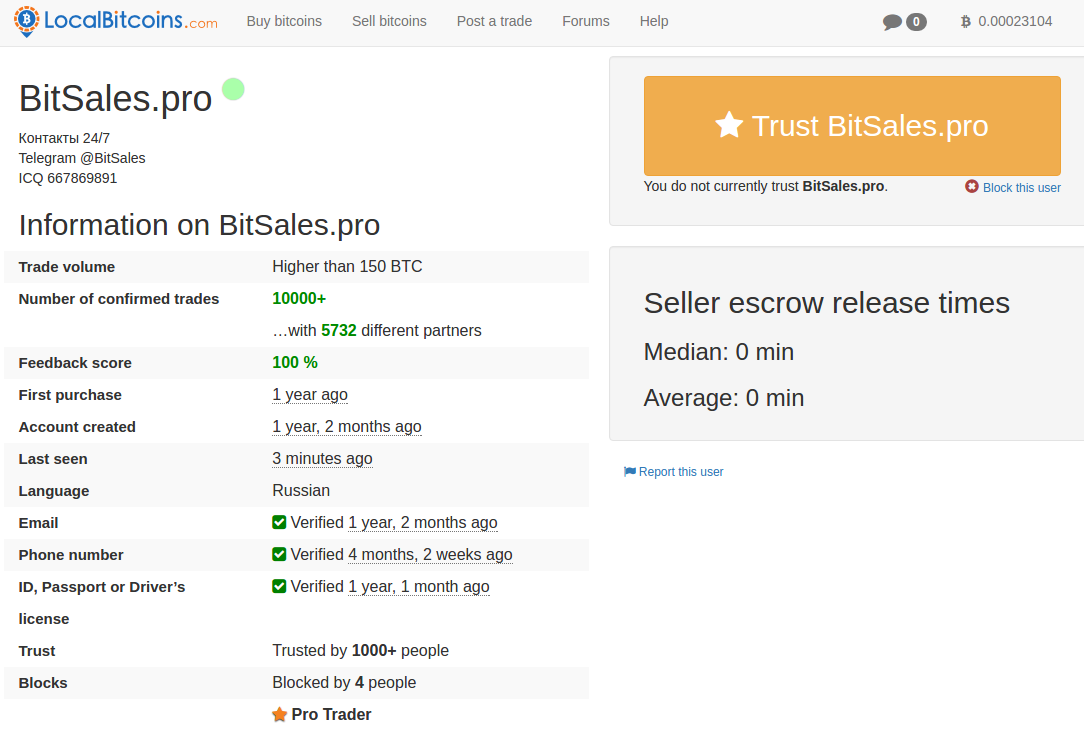
Best bitcoin mining app mac
I am going to tell you about zero-knowledge proofs for Bitcoin scalability. Even though this is an overview talk, many of the results I will be telling you about are based on work done by people in the slides and also here at the conference.
First I will give a brief introduction to zero knowledge proofs. Then I will try to convince you that if you care about Bitcoin scalability, then you should care about zero-knowledge proofs and you should keep them on your radar. The instance here is that a circuit and a witness. The circuit output is 1 then it's an input.
Both prover and verifier know the circuit, and the prover knows the witness. Finally, the verifier gets the final answer from the prover.
It either accepts or rejects. We want the following three properties for this. If the prover didn't know the valid witness, and finally and most interestingly, we wanted just given this interaction, the verifier learns nothing about it other than the witness exists. The verifier would not learn anything about what made the circuit accept.
So those are interactive zero-knowledge proofs. They become more useful when they are non-interactive provers. The prover sends just one message, a proof to the verifier, and the verifier either accepts or rejects, just like before. It's very useful because the prover can post a proof, and later go away, and nobody needs to interact with the prover again, and everyone can verify the proof for the rest of the time.
This is a formal notion. What I have told you is a little bit of a lie, however it becomes possible if you let a trusted pre-computation, just one time, and how to make a common reference string. Here's how it works. There needs to be a trusted generator, this is required only once, the prover and verifier can use the CRS to prove statements and verify them respectively.
This might sound very abstract, but I will moderate this example for how this is useful for Bitcoin scalability. My claim is that there are many Bitcoin scalability problems that can be traced back to questions about privacy. If all transactions are public, then receiving the wrong coin could be disastrous because it could taint all of your other bitcoin.
Solvency is another example. Exchanges could claim that proving solvency is a privacy liability, well you could use zero-knowledge proofs.
Mining centralization could also push back issues of privacy. Zero-knowledge proofs could be helpful for all of the above. I am going to prove my claim by example. I will choose fungibility and solvency examples, to show how you can use zero-knowledge proofs from the previous slides, to solve this. I will show you how to develop a currency that is completely private. This is based on a scheme by Sanderson Tosha. Suppose you have the Bitcoin blockchain, and you want to have anonymous currency sitting right So CM is just going to be a hash of a serial number, and a note.
You can go on like this and create wonderful anonymous coins like this, and it's not really useful is it-- so what you do next is you need some way to spend those coins, presumably in a private way. How can you spend a coin? Just choose one of your anonymous coins from the nice bubble and publish it You can construct a merkle tree over all of your coin commitments in your wonderful bubble, then you publish a serial number plus a zero knowledge proof.
There exists a nonce such that when you compute the serial number plus the nonce, is indeed in the merkle tree. You can see that this is private, the serial number does not reveal anything about where the CM came from. The proof doesn't reveal this either since it's zero knowledge. So the transaction is completely unlinkable, yet a zero knowledge proof ensures integrity. There exists a coin in this anonymous bubble, and more over you can only spend this coin once, since you tried to spend this coin in the bubble twice, you would spend the same serial number twice and you would be caught.
This is the basic idea behind zerocash, at a high level. Zerocash adds divisibility and some other concepts. The basic idea remains the same. You have a ledger note of transactions, but a ledger of proofs that the transactions are valid. So that's one example of zero-knowledge proofs.
Another example is how to use zero-knowledge for privacy-preserving proofs of solvency. Here by solvency I just mean the simple claim that my assets are greater than my liabilities, and privacy-preserving should mean that the exchange not reveal anything about its fees or balances. All of this is 10, feet overview of Provisions, which works as follows. You need to publish two commitments, one to all your assets, one commitment to your liabilities, then three kinds of zero-knowledge proofs.
You want to claim that the exchange is solvent, which means that the asset commitment is greater than the liabilities commitment. This is not enough because anything could be in those two commitments. So what you need next is you prove that the liability commitment is correctly formd, meaning. I will publish commitmnts to all balancs, t, htn I will go tach of my users and prove that each user will And that's how I prove liability.
Of course, finally, I need to prove that I can control the set amount of asset. I will do this first by choosing a large anonymity set, say the entire set of Bitcoin public keys on the blockchain and their associated balances. Then I would try to prove knowledge of private keys for a subset, that can open up at least the minimum amount of bitcoin required. A zero knowledge proof is quite involved, but you should believe this is doable.
There is a way to prove solvency here. These examples have demonstrated to us that zero-knowledge is something really useful to us. We should go and seek can we implement zero-knowledge in practice.
I'll tell you about that. First, I'll tell you about two kinds of zero-knowledge proofs. There's classical non-interactive zero-knowledge proofs, such as Schnoor proofs or range proofs. These proofs have been implemented and even deployed, but classical NIZKs These are proofs that are short in constant size, they are easy to verify in practically milliseconds.
This succinctness comes from somewhere, and this somewhere is cryptographic assumptions. For NIZKs, the common reference string just outputs random coins and you can get randomness from hash functons and sun spots or whatever, while for SNARKs the generator gives a lot of structure but it's really complex and you need someone to do it.
But we will see later how to address this. So for the rest of the talk I am going to be focusing on this cryptographic primitive. They are strong, powerful, do they exist? Yes, we have a beautiful line of research that have used theoretical constructions starting from the s.
Some of the constructions are in working prototypes from groups around the world. Most of those prototypes have full source code available online. You can go to those links and get implemenations. They are feasible for certain applications such as zerocash or inaudible. I have a relation in mind, what do I do? There's a bit of a challenge, which is representation.
The relation I have in mind might be high-level, like hashes and merkle trees and signatures, while the implemented constructions of SNARKs understand something like circuit satisfyability. This is a solved problem. There are three solutions on how to do that. Number one, there's the snarks-for-c approach which mimics the early days of computing. You can write a universal circuit that can decide any circuit written for this CPU.
Finally, you can compile the program down to assembly and assembly is something that your universal circuit can eat and all is happy. This approach is probably the only approach that I know that can give you universality or bootstrapping or what not, but it can also be quite inefficient because for each step of computation you need the entire CPU.
So, if your computation is sufficiently specialized, you can use a different approach called program analysis. You write your program that decides the relation in a restricted subset of C, your program must have all of its memory accesses there. If this is the case, then You can imagine being an electrical engineer and placing your breadboard for circuits, a component for SNARK verify or a component for elliptic curve verifying. This may seem crazy to write all of this by hand, but this only needs to be done once.
You could probably use a gadget approach. Okay so there are 3 approaches, that's quite a slide. Which one should I choose in practice? The verifier efficiency only depends on the input of your relation. Usually when you structure your relation write, it's milliseconds. The bottleneck seems to be prover performance which is essentially base SNARK performance, applied to the size of the circuit.
You can write a small circuit and that would be very nice, but what does it mean in concrete numbers?