



Mezcla de colores azul verde
24 comments
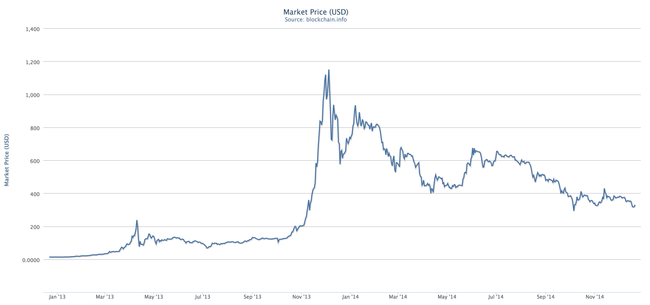
Casascius bitcoin 2011 hyundai tucson
The following is a list of machine learning, math, statistics, data visualization and deep learning repositories I have found surfing Github over the past 4 years. AlwaysRemember - Zipfian capstone project - Dan Morris. Its primary focus is on being generic, clean, and powerful without sacrificing much efficiency. Breeze is the merger of the ScalaNLP and Scalala projects, because one of the original maintainers is unable to continue development.
The Scalala parts are largely rewritten. Please improve and discuss! Conjecture - Scalable Machine Learning in Scalding. Train Convolutional Neural Networks or ordinary ones in your browser. CoverTree - Python implementation of cover trees, near-drop-in replacement for scipy. Data-Analysis-and-Machine-Learning-Projects - Repository of teaching materials, code, and data for my data analysis and machine learning projects. DeepLearningTutorials - Tutorials from deeplearning.
Pre-trained deep neural networks. Your agents are standing by! Other repos in the IPython organization contain things like the website, documentation builds, etc. Content moved to https: Uses Extreme Learning Machines and hyperopt. Kaggle-Competitions - All Kaggle competitions. This book takes a minimally mathematical approach, focusing on building intuition and experience, not formal proofs. Includes Kalman filters, Extended Kalman filters, unscented filters, and more. Includes exercises with solutions.
Kayak - Kayak is a library for automatic differentiation with applications to deep neural networks. LearnDataScience - Open Content for self-directed learning in data science. It handles dependency resolution, workflow management, visualization etc.
It also comes with Hadoop support built in. MechanicalSoup - A Python library for automating interaction with websites. Metronome - Suite of parallel iterative algorithms built on top of Iterative Reduce. Bringing the python data stack to the shell prompt. Bayesian Stochastic Modelling in Python. Statistical Data Analysis in Python. PythonicPerambulations - A port of jakevdp. Regions with Convolutional Neural Network Features.
This is outdated, check out scipy-lecture-notes. SimpleAintEasy - A compendium of the pitfalls and problems that arise when using standard statistical methods. SparseConvNet - Spatially-sparse convolutional networks. Allows processing of sparse 2, 3 and 4 dimensional data. Advances in Neural Information Processing Systems, Integrates with Apache Storm. TextBlob - Simple, Pythonic, text processing—Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more.
Theano-Lights - Deep learning research framework based on Theano. Theano-Tutorials - Bare bones introduction to machine learning from linear regression to convolutional neural networks using Theano. ThinkBayes - Code repository for Think Bayes.
Variational-Autoencoder - Implementation of a variational Auto-encoder. Back To Blog Posts The following is a list of machine learning, math, statistics, data visualization and deep learning repositories I have found surfing Github over the past 4 years. Pre-trained deep neural networks gender-data-pkg - A data package for R containing historical data sets about gender gensim - Topic Modelling for Humans getting-started-with-haskell - notes on where to find Haskell tutorials and tips to complete them ggplot-tutorial - Ghost - Just a blogging platform githut - Visualization of data from github archive.
Cats competition kaggle-galaxies - Winning solution for the Galaxy Challenge on Kaggle http: Bringing the python data stack to the shell prompt panns - Python Approximate Nearest Neighbor Search in very high dimensional space with optimized indexing. ThinkStats2 - Text and supporting code for Think Stats, 2nd Edition thumbor - thumbor is an open-source photo thumbnail service by globo.